3D 手游性能优化技巧
文章目录
前言
随着 3D 手游的品质要求越来越高,游戏画面表现越来越好,对于性能优化的需求也越来越迫切。但是手机硬件平台有其自身独特的特性–资源有限(CPU、GPU 和内存有限)和低功耗,这些都约束了硬件图形管线和引擎渲染管线的设计与实现。

作为一个游戏开发者,了解这些硬件特性和管线特点非常重要, 它能帮助我们在以后做游戏性能优化时,头脑中始终拥有 Big Picture, 做起优化来事半功倍。
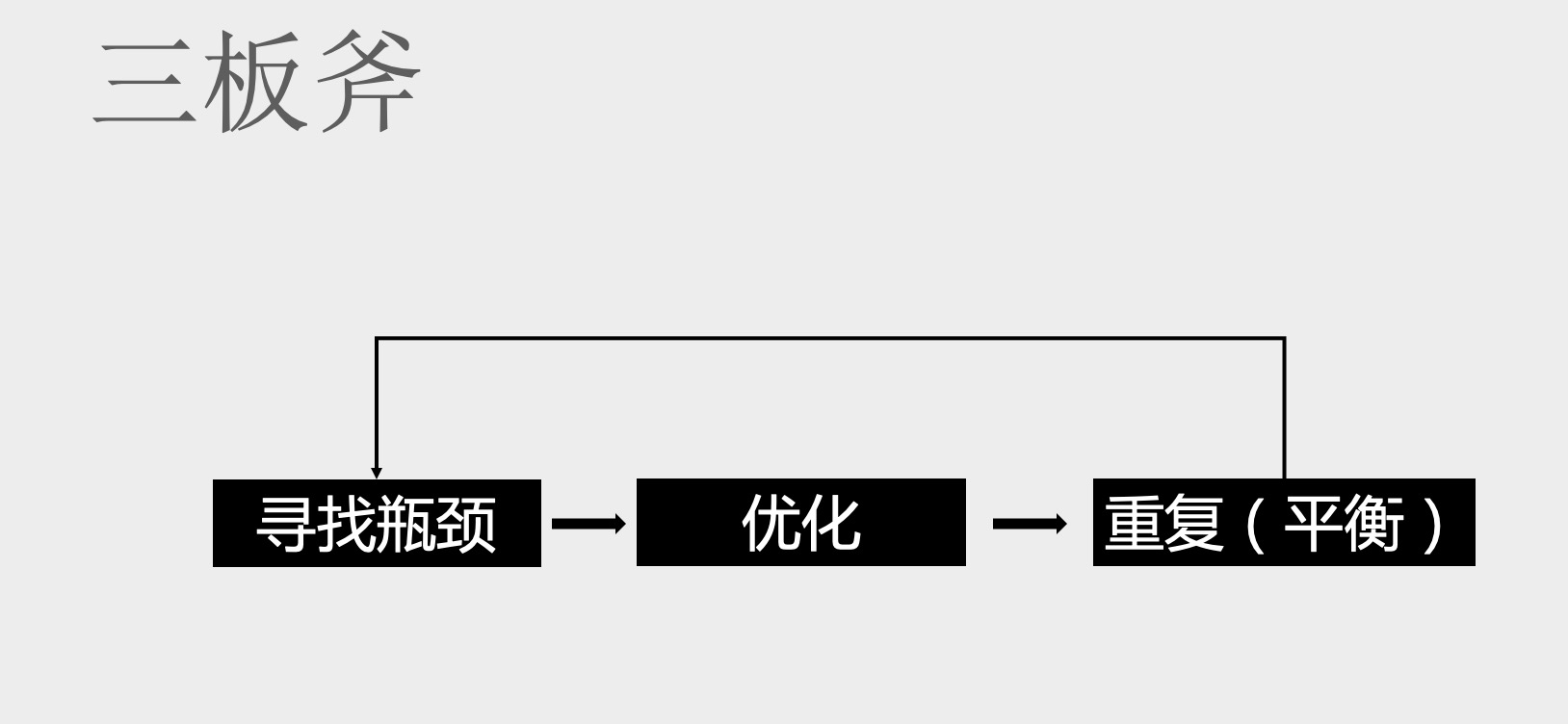
做性能优化最忌讳一上来就是“干”,一顿操作猛如虎,一看帧率 25.
性能优化平身就是一个平衡的艺术,我们需要花 20% 的努力达到 80% 的效果。在优化之前一定要先定位出性能瓶颈,针对瓶颈进行优化才来有明显的效果。
移动平台硬件特点
移动平台的硬件基本都是围绕“低功耗”来设计的,由于移动端不像 PC 端拥有无穷的电能,专业的显卡和专门的散热器,移动端的 GPU 内的显存(on-chip memory) 非常有限,通常我们说移动端的显存是跟主存共享的,电池容量也是有限的,并且很多手机都无法配置一个专业的散热器。所以,移动端针对这些重新设计了新的渲染管线–Tile-Based Rendering(TBR).
下面是桌面平台的渲染管线架构图(Immediate Mode Rendering, 简称 IMR):
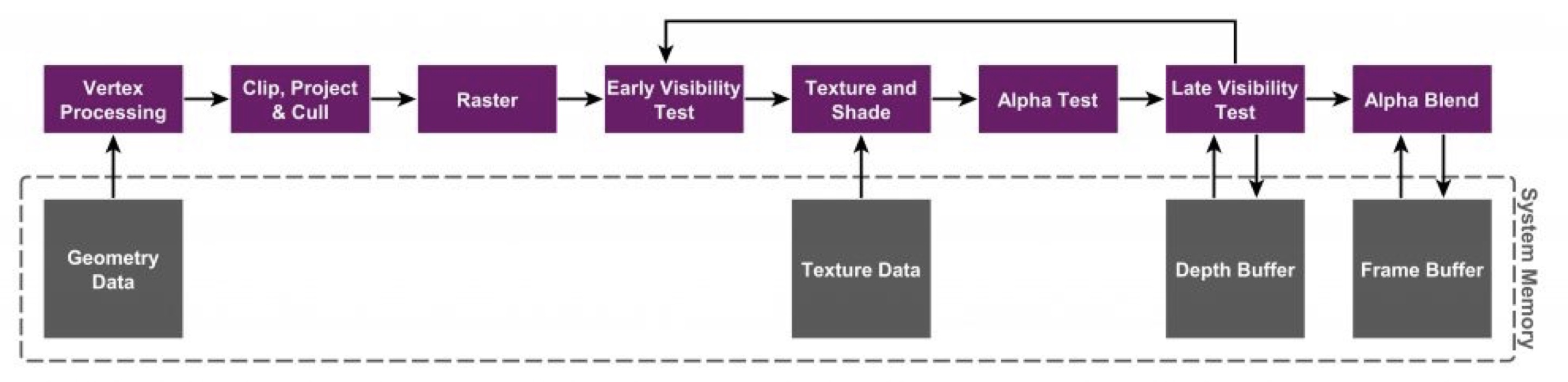
IMR 是 PC 和主机 GPU 使用的渲染方式,是指:每一次渲染 API 的调用,都会直接绘制图形对象。因此,每一次物体颜色和深度的渲染,都要读写 Frame Buffer 和 Depth Buffer (深度缓冲)。这种架构设计需要大量的带宽和专门的总线,同时需要 L1 和 L2 Cache 来解决带宽问题。而移动端的 GPU 尺寸非常小,并且功耗非常低,是不可能提供这样大的带宽的 支持的。
为了降低功耗的同时还能最大化性能,移动端设计了 TBR 和 TBDR(Tile-Based Defered Rendering), 下面是移动平台的 TBR 渲染管线架构图:
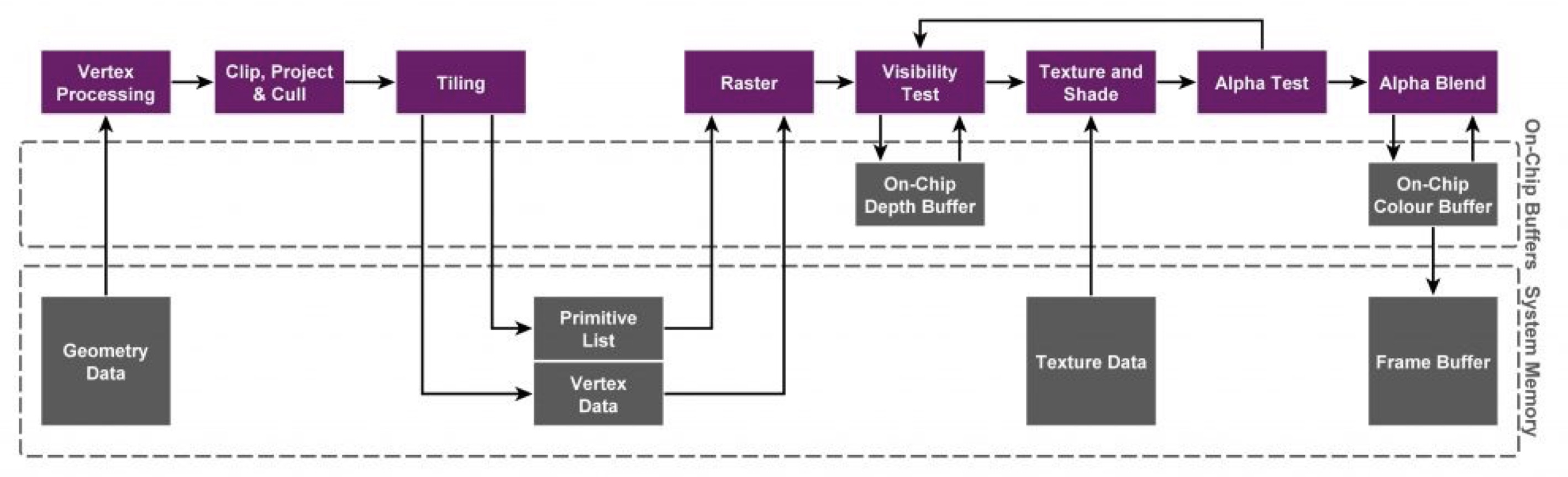
具体实现上是:渲染时直接渲染对象不再是当前的 Frame Buffer 和 Depth Buffer (深度缓冲),而是叫 Tile Buffer 的高速缓存。从而将 IMR (Immediate Mode Rendering)中对 Color/Depth Buffer 进行的读写操作,改为对 GPU 中高速内存的读写操作。MSAA 和 Alpha blend 都在 On-chip memory 上,所以它的效率非常高。另外,关于 Overdraw 的讨论也是在 on-chip memory 之上,当往主存写入 FrameBuffer 数据时是不存在 Overdraw 的。而 TBDR 渲染中的 HSR(Hidden Surface Remove) 技术可以保证不透明像素在 Tile Memory 上面也不存在 Overdraw.
下图是 TBDR 的渲染构架图:
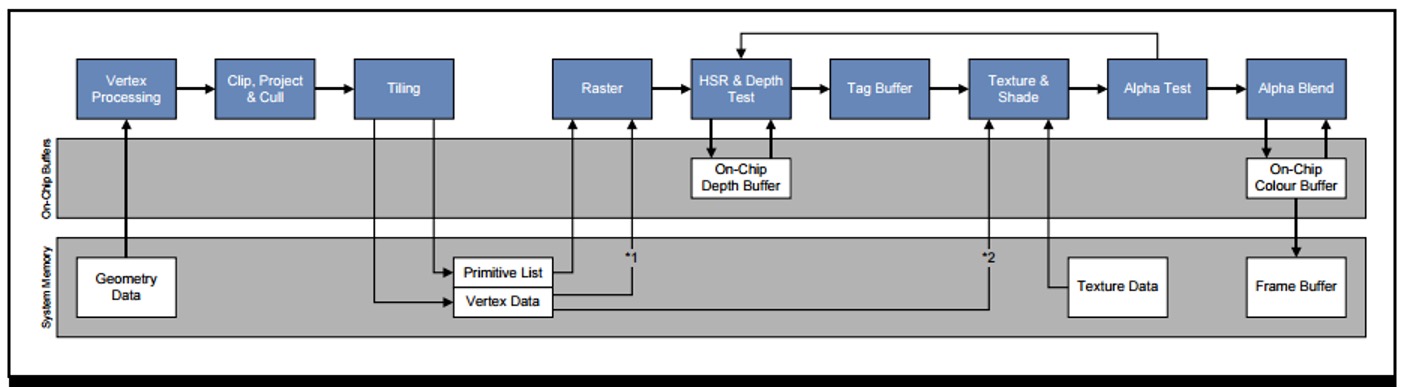
更多详细的 TBR 和 TBDR 介绍可以参考这篇知乎文章:
渲染管线中的任何一个阶段发生 Stall 都有可能变成管线中的瓶颈。由于 GPU 是高度并行化的硬件架构,这些单独的管线处理单元成为瓶颈的可能性一般不大(Pixel Shading 除外),更多的瓶颈可能发生在管线与主存的交互阶段,如下图所示:
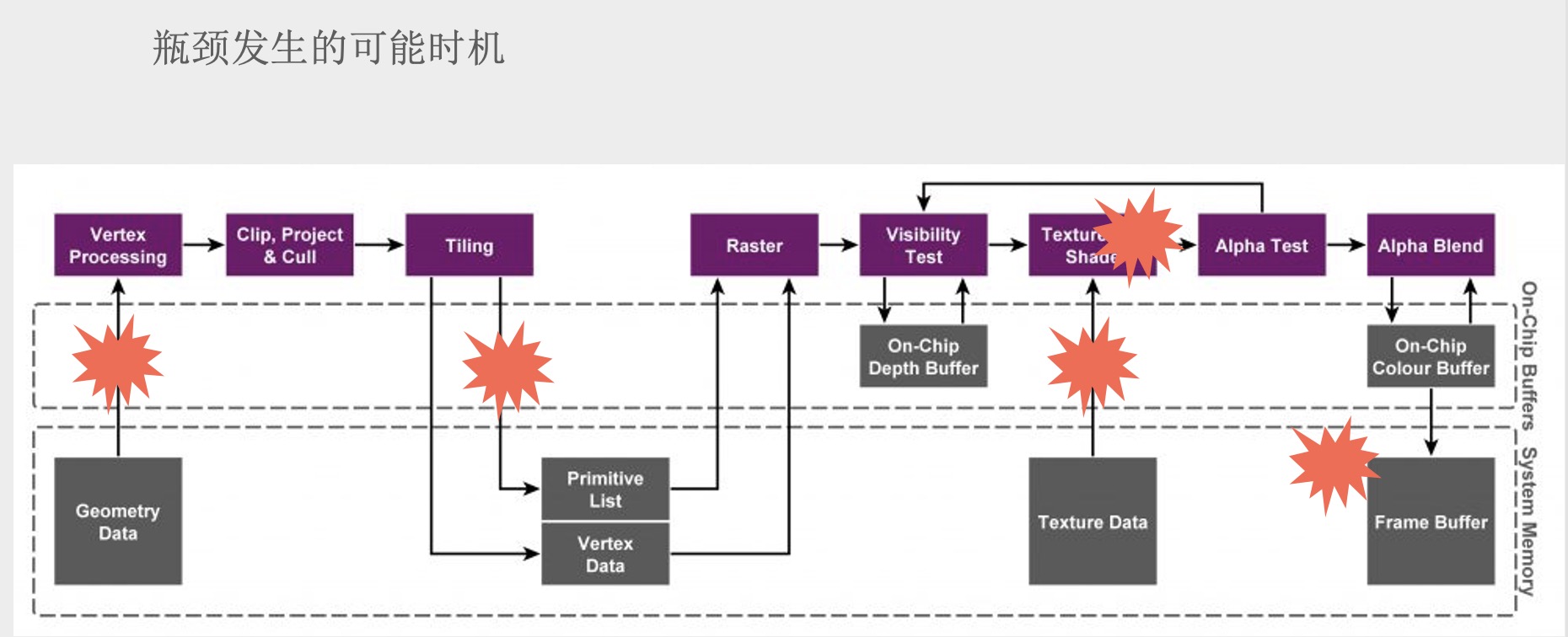
引擎渲染管线
针对移动端的 GPU 渲染管线,硬件厂商推出了 OpenGLES 图形 API 来进行 GPU 编程。由于 OpenGLES 本身的一些限制,最新的图形 API 提供了更多操作底层资源的能力,这些能力可以更进一步地减少管线的状态切换和降低功耗,比如 Vulkan 和 Metal。而游戏引擎就是利用这些 API 尽可能高效地提交渲染数据交给硬件去处理。
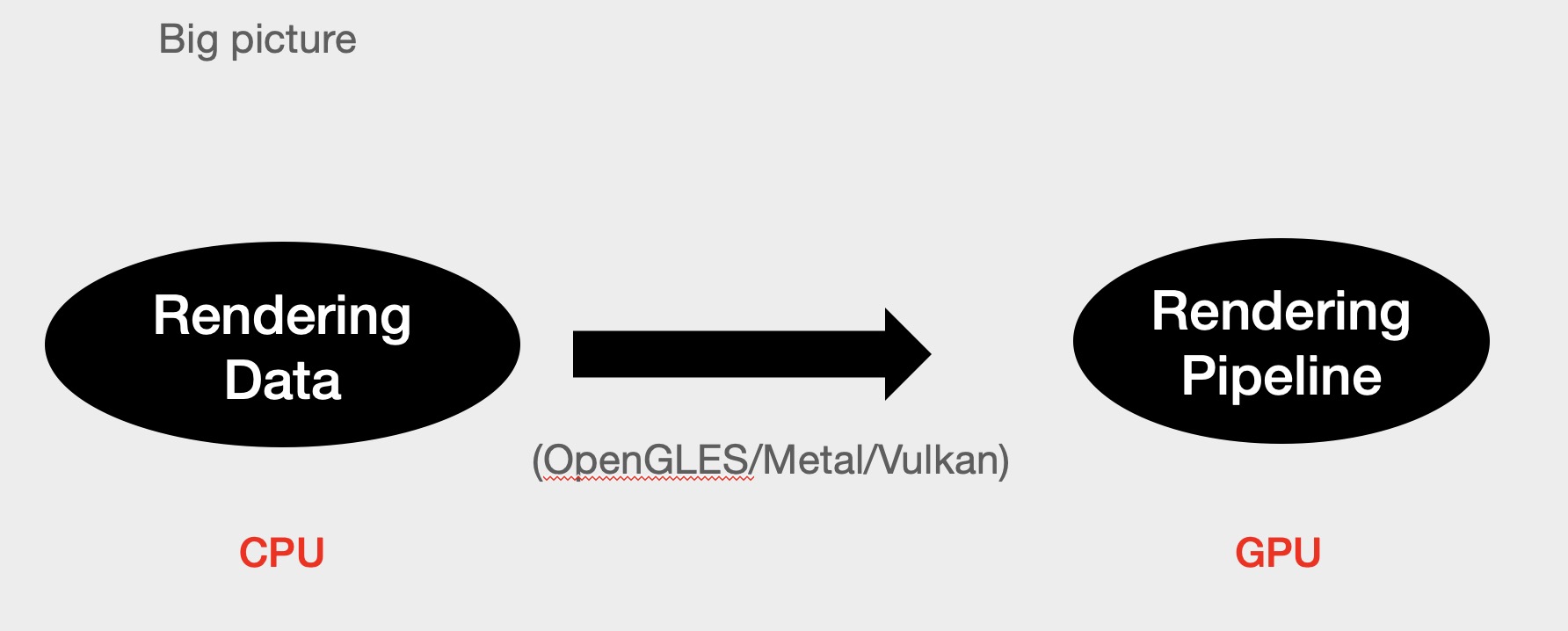
CPU 端主要负责准备渲染数据并告诉 GPU 如何渲染,而告诉 GPU 怎么渲染比 GPU 实际去渲染的速度要慢得多!
渲染引擎的优化手段主要是两点:Culling 和 Batching, 并且通过合理的 Sorting 来减少管线的状态切换。
这里为什么要单独把 Sorting 拉出来讲呢?因为一般为了优化性能,我们针对不透明的物体会以从前往后的顺序来排序,这样就可以利用管线的 depth-testing 来丢弃到看不见的像素。也可以利用一些 Early-Z(或者 depth prepass) 的技术在 Pixel Shading 之前就把这些看不见的像素剔除掉。但是,在 TBDR 架构中,由于硬件支持 HSR, 此时针对不透明物体的排序其实已经变得没那么重要了,可以把节省出来的 CPU cycle 做其他的事情(比如物理或者动画),关于排序的优化可以参考 这篇文章。
优化瓶颈
有了前面这些知识铺垫,接下来我们来深入了解一下影响游戏性能的三个主要瓶颈:CPU 瓶颈、GPU 瓶颈和带宽瓶颈。
CPU 瓶颈
一般来说,你的游戏瓶颈很容易出现在 CPU 端。首先你需要排除你的游戏中可能存在的逻辑瓶颈(物理,动画,AI,Update 复杂计算,同步 IO,GC 等)。针对这些逻辑问题,你可以采用对象池、分帧,异步 IO, 逻辑帧和渲染帧分开设置,使用简单的物理碰撞而不使用真实的物理模拟,避免复杂的运算每帧被反复调用。如果是使用脚本语言,需要避免 GC, 把计算密集型操作放到原生层来做。
一般游戏引擎都会提供一个场景树的概念,尽量使用扁平的场景树结构,减少场景树的复杂度(可以按需加载需要的内容)。
这里面对于渲染性能影响最大的就是减少 Draw Call 。减少 Draw Call 的核心点就是 Culling 和 Batching.

Culling 是为了尽可能少画一些内容。另外,如果引擎的 Culling 系统不是非常完备,或者 Culling 设置出现问题的时候,需要实际抓帧去确认想要 Culling 的元素是否真的生效了。

Batching 是为了每次画的时候,尽可能一次多画一些内容。 Batching 如果在 CPU 端做,大多数是空间换时间或者把瓶颈转移到 CPU 。而在 GPU 端做则是最大化利用硬件的并行能力,但是其本身的限制也不少。
下面是 Cocos Creator 的合批处理及其最佳实践:

GPU 瓶颈
GPU 的瓶颈,如果 Draw Call 数量合理的情况下,一般来说会主要表现在 FS(Fragment Shader) 指令太复杂和高带宽占用。但是其他任何阶段也都可能会产生瓶颈,比如你的三角形面数超过一定阈值,一般移动平台可能是 50w 面到 150w 面之间,就容易在 Tiling 阶段产生性能瓶颈。还有一点就是高 Overdraw 也会导致 GPU 多做很多无用功。

带宽瓶颈
由于硬件的限制,移动端的带端非常得有限,而很多延迟渲染技术和后处理技术未能在移动端广泛应用的原因也来源于带宽限制。
一般来说,使用压缩纹理可以极大地减少带宽占用。另外,对于 PBR 的渲染,要尽可能把 PBR 的材质中使用到的纹理合并到一张贴图中去(比如常见的高光贴图,金属度贴图和阴影贴图等可以合并到一张纹理)。如果需要使用多个 RT(Render Target) 的时候,尽可能限制 RT 的尺寸和格式。
那么怎么知道你的程序会不会是带宽瓶颈呢? ARM 在 2019 年给出了一个推荐值:2GB/s

如果你的游戏跑 60 帧,那么每帧可用的带宽将会是 2*1024/60 = 34M, 假设你的 GBuffer 的分辨率是 1280 * 1080,那么写一次 GBuffer(RGBA 4 个字节)的带宽大小为: 1280*1080*4/1024/1024 = 5.2M, 如果 3 张则是 15.6M.
考虑到一般你的游戏都会有 Overdraw, 假设 Overdraw 比较合理在 1.5 左右,那么这样的带宽消耗就能占到 15.6 * 1.5 = 23.4 M。 考虑到你还要渲染场景,ui 和角色等内容,这样很容易就超过了每秒 34M 的推荐带宽占用。
性能优化检查步骤
笔者也提供了一个一般化的性能瓶颈查找流程,仅供参考:
使用 PerfDog 连上手机看看能否跑满帧
查看 CPU 和 GPU 的使用率,尽可能低于 50%
使用 profiling 工具来 profile cpu 的开销(chrome 和 xcode 的 time profiler)
动态剔除游戏场景中的一些元素(比如场景、角色、特效等),观察对帧率、 CPU 和 GPU 的使用率的影响
针对影响大头分析是 CPU 瓶颈、GPU 瓶颈还是带宽瓶颈。
项目初期制作美术资源规范,提供工具自动检查和处理资源非常重要!!!
性能优化工具推荐
性能优化一定要借助 Profiling 工具,本小节会推荐一些常用的工具:
RenderDoc: https://renderdoc.org
Xcode:非常适合查找渲染管线级别的瓶颈。
Web: Chrome, inspector.js
Mali offline shader compiler:https://zhuanlan.zhihu.com/p/161761815
Snapdragon profiler: 抓帧工具,可以统计 heavy drawcall 和 overdraw
性能优化 Tips
实际开发过程中,不可能遇到任何小问题都去真机抓帧调试,如果能有一些最佳实践或者一些性能 Checklist 的话,可以帮助我们更快地定位性能问题。本小节就提供了 10 点小 Tips 供大家参考:
优化场景和角色 (LOD,Unlit, 合并贴图,减少 camera 和光源数量,使用合批和 bake)
优化 ui (减少 overdraw),避免系统字体,使用 SDF 字体。
优化阴影和光照 (避免实时光照和实时阴影,减少阴影精度和尺寸)
树叶、草地等(尽可能使用 GPU instancing)
优化 shader 计算,使用 textureLod,避免 alpha test 和 discard,避免 3 线性采样和各性异向采样。
除 ui 外,尽可能开启 mipmap(空间换时间)
优化特效,尽可能使用 POT 的纹理,减少透明区域,少叠加,少粒子
优化带宽:减少后处理,使用合适格式的压缩纹理
如果瓶颈不能消灭,就需要转移瓶颈(从 CPU 移到 GPU,computer shader, GPU skinning, Animation Bake, GPU particles etc)
砍美术效果(或者 Fake 表现)
性能优化 Tricks
有 Tips 必有 Tricks, 这些小 Tricks 都是从业内的一些老司机那里学来的,相信很多人也用过了,这里按例也提供 10 条,更多的小技巧需要读者在平时开发中自己总结和提炼,也欢迎大家留言评论与我分享。
不要按照屏幕的真实分辨率去设置 Framebuffer
多个 RT,可以限制 RT 的更新频率和分辨率
Bake 3D 场景为 skybox,低端机使用 skybox
修改 ui shader (游戏 color 的乘法)
shader 变量精度,除了 position 外,都使用 half 格式, mediump over highp
播放全屏特效或者弹窗时,可以使用 RT 屏蔽背景
使用假的效果:假阴影(贴片阴影)和假水(uv 扰动)
shader 编译链接,大纹理和大 buf 的加载放在开局
细节不突出的地方,降低材质复杂度,降低纹理精度,降低 shader 复杂度
合理使用公告板(朝着相机的面片和贴图来 fake 模型)
结语
最后,性能优化是一个非常依赖理论和经验的领域,水其实是非常深的,而且一直在不断地进化。本文最后提供了一些业内最新的性能优化文档,这些都是芯片厂商提供的,相信对于我们了解性能问题发生的根本原因会非常有帮助,本文的很多信息也来源于这些资料。
https://docs.imgtec.com/Profiling_and_Optimisations/PerfRec/topics/c_PerfRec_introduction.html
游戏引擎的官方文档 (这里去各自引擎的官网查找即可)